완전 이진트리(Complete Binary Tree)

완전이진트리
1) 완전 이진트리는 마지막 레벨을 제외 하고 모든 레벨이 완전히 채워져 있다.
2) 마지막 레벨은 꽉 차 있지 않아도 되지만, 노드가 왼쪽에서 오른쪽으로 채워져야 한다.
3) 마지막 레벨 h에서 1~2h-1 개의 노드를 가질 수 있다.
4) 완전 이진 트리는 배열을 사용해 효율적으로 표현 가능하다.
전 이진트리(Full Binary Tree)

전이진트리
1) 전 이진트리는 모든 노드가 0개 또는 2개의 자식 노드를 갖는 트리이다.
포화 이진트리(Perfect Binary Tree)

1) 포화 이진트리는 모든 레벨이 노드로 꽉 차 있는 트리를 뜻한다.
2) 전 이진트리의 성질도 만족해야 한다. 즉 모든 노드가 0개 혹은 2개의 자식 노드를 갖는다.
3) 모든 말단 노드가 동일한 깊이 또는 레벨을 갖는다.
4) 트리의 노드 개수가 정확히 2^k-1 개여야 한다. 여기서 k는 트리의 높이다.
자료(key)의 중복을 허용하지 않음
왼쪽 자식 노드는 부모 노드보다 작은 값, 오른쪽 자식 노드는 부모 노드보다 큰 값을 가짐
자료를 검색에 걸리는 시간이 평균 log(n) 임
inorder traversal 탐색을 하게 되면 자료가 정렬되어 출력됨
트리순회
전위 순회 (Preorder Traversal)
전위 순회는 깊이 우선 순회(DFT, Depth-First Traversal)이라고도 합니다.
트리를 복사하거나, 전위 표기법을 구하는데 주로 사용됩니다.
트리를 복사할때 전위 순회를 사용하는 이유는 트리를 생성할 때 자식 노드보다 부모 노드가 먼저 생성되어야 하기 때문입니다.
전위 순회는 다음과 같은 방법으로 진행합니다.
- Root 노드를 방문한다.
- 왼쪽 서브 트리를 전위 순회한다.
- 오른쪽 서브 트리를 전위 순회한다.

Preorder Traversal
위 트리에 전위 순회 결과는 다음과 같습니다.
A→B→D→E→C→F→G
중위 순회 (Inorder Traversal)
중위 순회는 왼쪽 오른쪽 대칭 순서로 순회를 하기때문에 대칭 순회(symmetric traversal)라고도 합니다.
중위 순회는 이진 탐색트리(BST)에서 오름차순 또는 내림차순으로 값을 가져올 때 사용됩니다.
내림차순으로 값을 가져오기 위해서는 역순(오른쪽-> root-> 왼쪽)으로 중위 순회를 하면 됩니다.
중위 순회는 다음과 같은 방법으로 진행합니다.
- 왼쪽 서브 트리를 중위 순회한다.
- Root 노드를 방문한다.
- 오른쪽 서브 트리를 중위 순회한다.
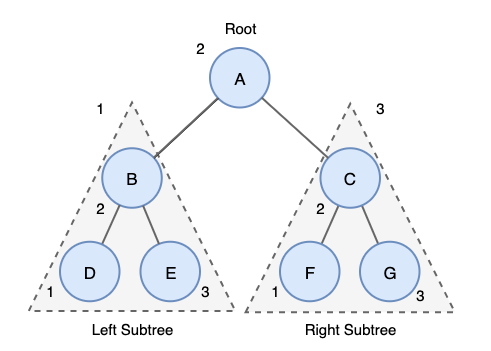
Inorder Traversal
위 트리에 중위 순회 결과는 다음과 같습니다.
D→B→E→A→F→C→G
후위 순회 (Postorder Traversal)
후위 순회는 트리를 삭제하는데 주로 사용됩니다.
이유는 부모노드를 삭제하기 전에 자식 노드를 삭제하는 순으로 노드를 삭제해야 하기 때문입니다.
후위 순회는 다음과 같은 방법으로 진행합니다.
- 왼쪽 서브 트리를 후위 순회한다.
- 오른쪽 서브 트리를 후위 순회한다.
- Root 노드를 방문한다.
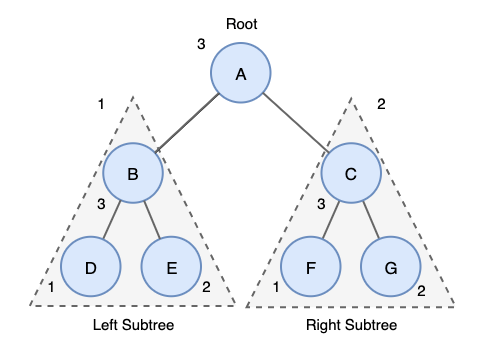
Postorder Traversal
위 트리에 중위 순회 결과는 다음과 같습니다.
D→E→B→F→G→C→A
코드로 표현
1. node
class TreeNode {
int value;
TreeNode left;
TreeNode right;
// Constructor
public TreeNode(int value) {
this.value = value;
this.left = null;
this.right = null;
}
}
public class BinaryTree {
TreeNode root;
public BinaryTree() {
root = null;
}
// 추가적인 메소드들 (삽입, 삭제, 탐색 등)
}
2. array
class BinaryTreeArray {
int[] tree;
int size;
public BinaryTreeArray(int capacity) {
tree = new int[capacity];
size = 0;
}
// 인덱스를 기반으로 트리의 왼쪽 자식, 오른쪽 자식 접근
public int leftChild(int i) {
return 2 * i + 1;
}
public int rightChild(int i) {
return 2 * i + 2;
}
public void addNode(int value) {
if (size < tree.length) {
tree[size++] = value;
}
}
}
그래프 (Graph)
: 정점과 간선들의 유한 집합 G = (V,E)
정점(vertex) : 여러 특성을 가지는 객체, 노드(node)
간선(edge) : 이 객체들을 연결 관계를 나타냄. 링크(link)
간선은 방향성이 있는 경우와 없는 경우가 있음
그래프를 구현하는 방법 : 인접 행렬(adjacency matrix), 인접 리스트(adjacency list)
그래프를 탐색하는 방법 : BFS(bread first search), DFS(depth first search)
그래프의 예)
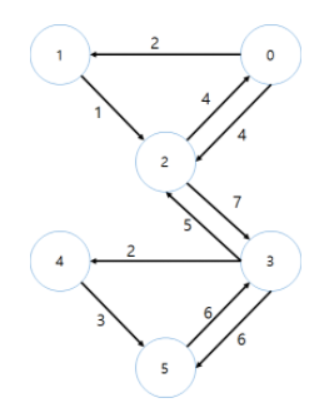
코드로 표현
1. 비방형 그래프
import java.util.*;
class Graph {
// 각 노드의 연결을 저장하는 맵
private Map<Integer, List<Integer>> adjList;
// 그래프 초기화
public Graph() {
adjList = new HashMap<>();
}
// 그래프에 노드 추가
public void addNode(int node) {
adjList.putIfAbsent(node, new ArrayList<>());
}
// 간선 추가 (비방향 그래프)
public void addEdge(int node1, int node2) {
adjList.putIfAbsent(node1, new ArrayList<>());
adjList.putIfAbsent(node2, new ArrayList<>());
adjList.get(node1).add(node2);
adjList.get(node2).add(node1); // 비방향 그래프이므로 양쪽에 간선 추가
}
// 그래프 출력 (인접 리스트 형식)
public void printGraph() {
for (int node : adjList.keySet()) {
System.out.print(node + " -> ");
for (int neighbor : adjList.get(node)) {
System.out.print(neighbor + " ");
}
System.out.println();
}
}
}
public class UndirectedGraphExample {
public static void main(String[] args) {
Graph graph = new Graph();
// 노드 추가
graph.addNode(1);
graph.addNode(2);
graph.addNode(3);
graph.addNode(4);
// 간선 추가
graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 4);
// 그래프 출력
graph.printGraph();
}
}
2. 방향그래프
public class DirectedGraphArray {
private int[][] adjMatrix;
// 그래프 초기화
public DirectedGraphArray(int size) {
adjMatrix = new int[size][size]; // 크기 `size`인 인접 행렬 초기화
}
// 간선 추가 (방향 그래프)
public void addEdge(int node1, int node2) {
adjMatrix[node1][node2] = 1; // 단방향 그래프이므로 한쪽 방향만 추가
}
// 그래프 출력
public void printGraph() {
for (int i = 0; i < adjMatrix.length; i++) {
System.out.print(i + " -> ");
for (int j = 0; j < adjMatrix[i].length; j++) {
if (adjMatrix[i][j] == 1) {
System.out.print(j + " ");
}
}
System.out.println();
}
}
public static void main(String[] args) {
// 노드 5개로 그래프 생성
DirectedGraphArray graph = new DirectedGraphArray(5);
// 간선 추가
graph.addEdge(0, 1);
graph.addEdge(0, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 4);
// 그래프 출력
graph.printGraph();
}
}
3. 가중치그래프
public class WeightedGraphArray {
private int[][] adjMatrix;
// 그래프 초기화
public WeightedGraphArray(int size) {
adjMatrix = new int[size][size]; // 크기 `size`인 인접 행렬 초기화
// 기본값을 -1로 설정하여 가중치가 없음을 표시 (0이면 가중치가 없는 간선이 되므로 -1 사용)
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
adjMatrix[i][j] = -1;
}
}
}
// 간선 추가 (가중치 포함)
public void addEdge(int node1, int node2, int weight) {
adjMatrix[node1][node2] = weight; // 간선 추가
}
// 그래프 출력
public void printGraph() {
for (int i = 0; i < adjMatrix.length; i++) {
System.out.print(i + " -> ");
for (int j = 0; j < adjMatrix[i].length; j++) {
if (adjMatrix[i][j] != -1) {
System.out.print("[" + j + ", " + adjMatrix[i][j] + "] ");
}
}
System.out.println();
}
}
public static void main(String[] args) {
// 노드 5개로 그래프 생성
WeightedGraphArray graph = new WeightedGraphArray(5);
// 간선 추가 (가중치 포함)
graph.addEdge(0, 1, 10);
graph.addEdge(0, 2, 5);
graph.addEdge(1, 3, 2);
graph.addEdge(2, 4, 3);
// 그래프 출력
graph.printGraph();
}
}해싱
: 검색을 위한 자료 구조
키(key)에 대한 자료를 검색하기 위한 사전(dictionary) 개념의 자료 구조
key는 유일하고 이에 대한 value를 쌍으로 저장
index = h(key) : 해시 함수가 key에 대한 인덱스를 반환해줌 해당 인덱스 위치에 자료를 저장하거나 검색하게 됨
해시 함수에 의해 인덱스 연산이 산술적으로 가능 O(1)
저장되는 메모리 구조를 해시테이블이라 함
jdk 클래스 : HashMap, Properties

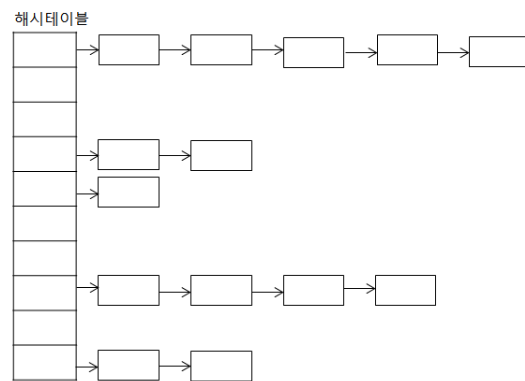
두 가지방식 모두 찾아봐야함
https://codechacha.com/ko/java-system-identityhashcode/
https://yoongrammer.tistory.com/70
'Algorithm' 카테고리의 다른 글
| 파스칼의 삼각형 (1) | 2024.12.13 |
|---|---|
| 이진트리탐색 - 전위, 중위, 후위 (0) | 2024.12.13 |
| 깊이 우선 탐색 - DFS(Depth-First Search) - dijkstra 다익스트라 (0) | 2024.12.13 |
| 넓이우선탐색 BFS(Breadth-First Search) (0) | 2024.12.13 |
| 에라토스테네스 체 (소수찾기) (0) | 2024.12.13 |
